# 防 API 重放攻击前后端完整设计
信息安全是一个永久的话题,一切信息安全措施与防范都是在加大不法犯罪的成本。而防 API 重放攻击就是是一项做了比没做好的安全功能。
# API 重放攻击是什么
API 重放攻击(Replay Attacks)又称重播攻击、回放攻击,这种攻击会不断恶意或欺诈性地重复一个有效的 API 请求。攻击者利用网络监听或者其他方式盗取 API 请求,进行一定的处理后,再把它重新发给认证服务器,是黑客常用的攻击方式之一。
# 例子
- HTTPS 协议下:a 用户向 A 服务发起私钥申请
- A 服务校验请求携带的凭据等信息确认没问题发放私钥,这时请求响应信息将发送给 a 用户
- 在 a 用户 向 A 服务发起请求跳转过程,b 用户抓包到了这条请求,但 HTTPS 协议下加密无法破解。
- 但 b 用户不关心这请求无法破解,他仅需要知道该请求的目标 A 服务的接口是发放私钥的接口,重新发起该请求。
- 假设 A 服务并未做安全措施,那么 A 服务将校验请求携带的凭据等信息确认没问题发放私钥,这时请求响应信息将发送给 b 用户
以上例子的私钥可以自行替换其它信息
# 防 API 重防攻击有什么用
除了可以避免上述例子,还可以优化两个特性【接口的幂等性】和【接口要求防止参数篡改】。
# 接口的幂等性
是以 "相同" 的请求调用这个接口一次和调用这个接口多次,对系统产生的影响是相同的。但在重复的请求下虽然保证了系统的安全,但依旧会消耗系统资源。API 防重可以尽量避免。
# 接口参数防篡改
恶意抓取或拦截调用端到服务端之间的请求,并调整参数继续发送给服务端,即使不法份子知道防篡改规则,也还有防重措施在,而且 API 防重可以和接口参数防篡改一起做。
单从爬虫上,就加大了爬虫的难度,在不能理解和破译加密规则的情况下,从接口级的数据爬取变成页面级的数据采集。
防 API 重放攻击措施在小型服务上好处极低,但业务请求量上来后,过滤重复请求将为系统节省不少资源。所以一般做在网关上
# 实现思路简述
服务环境简述:前后分离,后端微服务,网关自研分布式部署 (负载均衡算法)
- 为了确保每个请求唯一,我们为每个请求生成一个 UUID。
- 为了确保请求携带的 UUID 从调用端到服务端未被替换,我们对 UUID 加盐 hash 加密。
- 为了后端不无限存储 UUID,需要一个有效时间范围,前端再加一个时间戳 timestamp 一起加密,网关接收到的请求携带的时间戳 5 分钟以外的直接拒绝。
- 为了网关的性能,使用本地缓存,又因为网关是多节点部署,负载均衡算法改一致性 hash 算法。
- caffeine 每存储一个 UUID 内存占用比例约为 UUID 的三倍左右。为了减少内存的占用,且需求并不复杂,改为使用 Set 实现
# 后端设计细节与实现原理
# 设计细节之缓存
UUID 是 JAVA 中的基础数据类型,单个 UUID 128 位 16 进制后为 32 字节,也就是 32 byte,所以 2 千万 UUID 数据缓存本地内存中会产生大约 610MB 的大小。假设网关单节点 QPS 按照 2W 计算,也就是需要缓存最近 16 分钟 30 秒的 UUID 才能达到 2 千万数据量,只要设置合理时间内缓存 UUID ,节点不会出现内存溢出问题。
# 为什么存储 UUID
千万不用尝试存储 UUID 转换为 String 后的字符串,即使你去掉了四个 - 字符,依旧有 32 个字符,根据对象内存大小计算公式,在 64 位指针压缩的情况下。
空 String 对象内存大小
对象头(8 字节)+ 引用 (4 字节 ) + char 数组(16 字节)+ 1个 int(4字节)+ 1个long(8字节)= 40 字节 |
若 String 对象不为空,因为 char 类型占用 2 字节。
40 + 2 * n | |
// 所以 UUID 转字符串后若去掉四个 - 字符。最后 String 内存大小占用为 40+2*32 = 104 字节 |
所以若存储的是 UUID 的 String 对象,内存将会是直接存 UUID 的三倍。
# 为什么不用 caffeine 缓存
caffeine 是一个非常优秀的缓存框架,提供缓存超时,最开始也尝试使用了但因为数据量大起来的时候内存占用比较大,尤其是存储时必须 Key,Value 形式,多了一个 Value,因为底部是 HashMap。虽然使用 W-TinyLFU 优秀算法,但奈何我并不需要它,所以含泪放弃。
在追寻自行实现时,想过使用布隆算法,因为这回更加节省内存占用空间,但清理和可能误判不是第一次果断放弃,也想过时间轮,但因为觉得使用时间做分割的转盘每一块就是一个线程安全的 Set 。后期有效时间戳 timestamp 调整。会导致内存最低的上限拉高。最后采用了一个简短的时间链,每隔一段时间创建一个线程安全的 Set。不在有效时间的 Set 全部抛弃。
Set 集合生成代码
private Map<Long, Set<UUID>> timeRoulette = new HashMap<>(); | |
public RequestValidityVerifier() { | |
// 当前时间缩短 1 秒,以防止数据输入异常 | |
timeRoulette.put(System.currentTimeMillis()-1000L, Collections.synchronizedSet(new HashSet<>(7600))); | |
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor(); | |
executorService.scheduleAtFixedRate(()->{ | |
// 在创建时,更长的时间请求有可能落在前一个收集上 | |
long now = System.currentTimeMillis(); | |
timeRoulette.put(now, Collections.synchronizedSet(new HashSet<>(7600))); | |
// 添加桶的生成时间,以确保桶中的所有标记此时过期 | |
timeRoulette.keySet().removeIf(key -> now - key > 300000+60000); | |
},60000,60000, TimeUnit.MILLISECONDS); | |
} |
UUID 匹配逻辑代码。时间戳超过有效时间判断在前面处理了
public Boolean isSymbolExists(VerifyResult<UUID> verifyResult) { | |
// 从大到小 | |
List<Long> keyList = timeRoulette.keySet().stream().sorted((q,h)-> (int) (h - q)).collect(Collectors.toList()); | |
if(!keyList.isEmpty()){ | |
for(Long key : keyList){ | |
// 获取还在有效时间的桶,因为从大到小排序桶,最先匹配的就是要存放这个时间范围的桶,不可能存在下个桶就像 5 分钟不应出现在 10 分钟 - 20 分钟的桶之间。 | |
if((System.currentTimeMillis() - key) < MAX_TIMEOUT && key < verifyResult.getTimestamp()){ | |
Set<UUID> uuids = timeRoulette.get(key); | |
return uuids.add(verifyResult.getT()); | |
} | |
} | |
} | |
return false; | |
} |
# 为什么使用一致性 Hash 环
首先在缓存高效考虑下使用本地缓存,而不是 Redis 。如果使 Redis 那么在网关分布式节点下将不需要考虑下次请求缓存命中问题,因为所有节点的缓存都在 Redis 上,但这样会有额外的网络开销,且如果要保证 Redis 高可用下又会涉及到 Redis 集群。所以在各节点使用本地缓存是最优的选择,将问题变成了一个,如何同步缓存数据。
如何同步缓存数据这个问题,可以看到更本质的问题是缓存里面有,如何命中。所以我选择使用一致性 Hash 环 来解决这个问题,它可以保证有 A,B,C 三个节点。请求携带 a 密文第一次落在 A 节点。那只要携带 a 密文的请求将都会落在 A 节点。
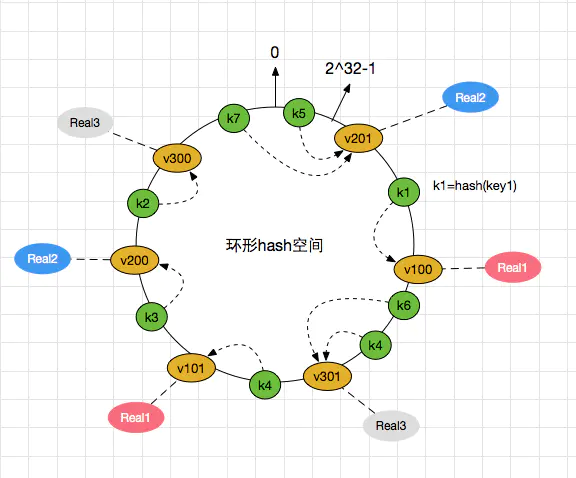
一致性 Hash 环原理:因为 Hash 值是 int,int 是 4 字节 32 位。其中一位代表正负,所以范围为 0-2^32-1,然后首尾相连构成一个环。
如何使用:A,B,C 三个节点 Hash 值为 10,100,1000。那么当 a 密文 Hash 值计算为 20 时落在 B 节点,150 时落在 C 节点,计算为 1 或者 1001 时落在 A 节点。顺时针存放最近一个节点。当然也可以逆时针,看代码实现。
使用虚拟节点:看到上面如果使用会注意到各节点 Hash 值分布不均,这时使用虚拟节点是将一个真实节点加上一些其它字符串如 (v300) Hash 成多个值,尽量使节点分布均匀。
完整结构图如下一个真实节点对应两个虚拟节点,实际情况根据不同的 Hash 算法初始化的虚拟节点数量也不一样
相关代码
Hash 算法
/** | |
* 使用 FNV1 32 HASH 算法计算服务器的 HASH 值 (虚拟节点最好在 150 以上) | |
* @param str | |
* @return | |
*/ | |
public static int getHash(String str) { | |
final int p = 16777619; | |
int hash = (int) 2166136261L; | |
for (int i = 0; i < str.length(); i++) | |
hash = (hash ^ str.charAt(i)) * p; | |
hash += hash << 13; | |
hash ^= hash >> 7; | |
hash += hash << 3; | |
hash ^= hash >> 17; | |
hash += hash << 5; | |
if (hash < 0) | |
hash = Math.abs(hash); | |
return hash; | |
} |
存储 / 删除 / 获取真实节点
private final static int VIRTUAL_NODES = 150; | |
private final SortedMap<Integer, String> virtualNodes = new TreeMap<>(); | |
// 存储 | |
public void addFactNodes(String ip) { | |
for (int i = 0; i < VIRTUAL_NODES; i++) { | |
String virtualNodeName = ip + "&&VN" + i; | |
int hash = getHash(virtualNodeName); | |
virtualNodes.put(hash, virtualNodeName); | |
} | |
} | |
// 删除 | |
public void removeFactNodes(String ip) { | |
int i = 0; | |
while(virtualNodes.containsValue(ip + "&&VN" + i)) { | |
virtualNodes.remove(getHash(ip + "&&VN" + i)); | |
i++; | |
} | |
} | |
// 获取真实节点 | |
public String getServer(String key) { | |
int hash = HashNodeUtil.getHash(key); | |
if(this.virtualNodes.isEmpty()){ | |
return null; | |
} | |
SortedMap<Integer, String> subMap = this.virtualNodes.tailMap(hash); | |
String virtualNode; | |
if (subMap.isEmpty()) { | |
Integer i = this.virtualNodes.firstKey(); | |
virtualNode = this.virtualNodes.get(i); | |
} else { | |
Integer i = subMap.firstKey(); | |
virtualNode = subMap.get(i); | |
} | |
if (!StringUtils.isEmpty(virtualNode)) { | |
return virtualNode.substring(0, virtualNode.indexOf("&&")); | |
} | |
return null; | |
} |
# 谁在同步这个 Hash 环
当然是” 注册中心 “在同步
# 前端设计细节与实现原理
需要给前端提供一个方法,最好是一个远程引用的 JS 这样便于统一维护和管理。前端加密使用 crypto-js。
crypto-js 的 CDN 地址,调试时远程引用,调试完复制 min 的 JS 到自身的 JS 上。这样前端只要引用一个地方。
使用 crypto-js 加密除了要知道后端的加密规则,还需要知道加密时将字符串转换字节的编码是什么,还有 UUID 是几版本的。不同的字节编码加密出来的密文是不一样的。
例子:后端使用 HmacMD5 加密后用 base64 处理,版本 4 的 UUID ,字符串转换字节的编码为 UTF_8。
未处理前 JS
<head> | |
<script src="https://cdn.bootcdn.net/ajax/libs/crypto-js/4.1.1/core.js"></script> | |
<script src="https://cdn.bootcdn.net/ajax/libs/crypto-js/4.1.1/hmac.js"></script> | |
<script src="https://cdn.bootcdn.net/ajax/libs/crypto-js/4.1.1/md5.js"></script> | |
<script src="https://cdn.bootcdn.net/ajax/libs/crypto-js/4.1.1/enc-base64.js"></script> | |
</head> | |
<body> | |
</body> | |
<script> | |
(function(root,algorithm){ | |
root.API = algorithm(); | |
})(this, function () { | |
// 版本 4 的 UUID 生成方法 | |
function RandomlyUniqueValue() { | |
var chars = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'.split(''); | |
var uuid = [], i; | |
var r; | |
uuid[8] = uuid[13] = uuid[18] = uuid[23] = '-'; | |
uuid[14] = '4'; | |
for (i = 0; i < 36; i++) { | |
if (!uuid[i]) { | |
r = 0 | Math.random()*16; | |
uuid[i] = chars[(i == 19) ? (r & 0x3) | 0x8 : r]; | |
} | |
} | |
return uuid.join(''); | |
} | |
var API = { | |
apiSymbol:function(){ | |
let timestamp = new Date().getTime(); | |
let uuid = RandomlyUniqueValue(); | |
let data = CryptoJS.enc.Utf8.parse(uuid+timestamp); // 获取要加密数据字符串的 utf-8 编码字节 | |
let key = CryptoJS.enc.Utf8.parse("123456789"); // 获取盐字符串的 utf-8 编码字节 | |
let value = CryptoJS.HmacMD5(data,key);// 加密得到 Hex 编码格式的字节 | |
let hexValue = CryptoJS.enc.Hex.stringify(value);// 通过 Hex 编码格式将该字节转字符串 | |
// 组装明文签名,获取字符串的 utf-8 编码字节 | |
let result = CryptoJS.enc.Utf8.parse(uuid+";"+timestamp+";"+hexValue); | |
return CryptoJS.enc.Base64.stringify(result); // 返回 base64 处理后的字符串 | |
} | |
}; | |
return API; | |
}) | |
console.log(API.apiSymbol()); | |
</script> |
如果有其它问题可以在控制台断点调试,看 crypto-js 的 js 实现。
然后再将前面例子里引用的四个 js 后面加上 .min 。获取它们的压缩文件,将所有压缩文件复制集中到自身这个 JS 。
然后通过 JS 混淆网站 混淆代码。可以使用默认或者自行研究配置
# 总结
唯有笔记和文章才让我感觉真学会了它