# 正则表达式的学习
正则表达式是计算机科学的一个概念,其表现形式是使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
# 熟知正则表达式一些细节知识
- 绝大部分编程语言都支持正则表达式,原因之一是正则表达式被广泛地应用于各种 Unix 或类 Unix 系统的工具中,而现在的 Linux 系统是 Unix 系统的一个分支,所以可以在 Linux 上跑的语言都可以实现正则。当然还有其他原因
- 正则表达式的功能本质只有一种:B 字符串在 A 正则表达式下有几处字符串满足。而编程语言一般常用的是基于以上实现的是否匹配方法,返回 True 或 False
- 正则表达式并非所有地方都是统一的,有些地方支持 \d 等价与 [0-9] , 而有些地方不支持。其根本原因是正则表达式整体分为基本正则表达式 (BRE) 和扩展型正则表达式 (ERE) 两个大流派。所以遇到相同正则两处地方返回结果不一样时可能就是两处地方的流派不同。如:Linux 系统中的 grep 默认使用正则表达式是 BRE,不支持 \d 格式,但使用 grep -P 时正则表达式是 ERE,这时支持 \d 格式识别
- 在部分语言中使用正则表达式或者需要经过多处传递解析时需要注意正则中的转义符 \ 该符号会以倍数的减少。如在 java 中 \ 反斜杠表示转义符,所以在使用 \s (匹配数字) 正则时前面还需要一个 \
- / 这个字符是不需要转义的
# 正则表达式拆分理解
本节将主要使用 JavaScript 语言支持的正则表达式 (ERE),这样可以通过 F12 在 Console 下复制体验,且 JavaScript 的正则语言默认处理的非常少便于理解
注:以下内容是个人理解,如有不对之处请果断指出,大家相互学习理解
# 正则表达式结构的首和尾
正则表达式的结构首是 / ,尾是 / 或者 /g 。尾的 / 是每次执行都是返回第一个匹配的值,尾的 /g 是第一次执行返回第一个匹配值,下一次执行返回第二个匹配值,以此类推直到无法匹配返回 null 这时再次执行又等于第一次执行,形成一个环。需要注意的执行的顺序和正则有关系,和需要匹配的字符串没有关系。看以下例子
有些语言做了封装不用写 “/”。像 nginx 配置中有 ^/(.*) 开头的
var regx = /a[2-3]/; | |
var data = "a2a3"; | |
var regxt = /a[2-3]/g; | |
regx.exec(data); // 匹配值为 a2,获取第一个匹配值 | |
regx.exec(data); // 匹配值为 a2, 执行多少次都没变化 | |
regxt.exec(data); // 匹配值为 a2, 获取第一个匹配值 | |
regxt.exec(data); // 匹配值为 a3,第二次执行获取第二个匹配值 | |
regxt.exec(data); // 匹配值为 null 第三次执行无任何匹配所以为 null | |
regxt.exec(data); // 匹配值为 a2 第四次执行又回到了第一次执行结果、至此进入循环 | |
regxt.exec(“a3a2"); // 匹配值为 a2 第五次执行等于第二次执行应该获取第二个匹配值,这里换了一个字符串,所以第二个匹配的值还是为 a2 | |
// 所以说字符串发生改变不会影响正则执行匹配顺序位,除非为 null 又从头开始 |
诸如像 ningx 中看到的 ^/(.*) 开头的正则若直接通过 js 使用是会报错的。但也有很多语言会封装这层,变成一个函数方便你使用。
# 正则表达式中匹配逻辑中的开始和结尾
正则表达式的匹配逻辑中的首是 ^ ,意味着从字符的首字母开始匹配正则,尾是 $ ,意味着字符串的结尾要结束匹配正则。若只有 $ 则匹配逻辑从后往前读
/123/.test("456712389"); //true 因为字符串中间有 123 字符串存在,所以匹配通过 | |
/^123/.test("456712389"); //false 因为字符串必须开头满足 123。 | |
/^123/.test("123456789"); // true | |
/123$/.test("123456789"); //false 因为结尾字符串不是 123 ,匹配不通过 | |
/123$/.test("456789123"); // true | |
/^123$/.test("123"); // 这样的正则仅字符串 ”123“能匹配通过。”123123“也不可以 |
^ 符号虽然代表从字符串首字母开始匹配,但使用 [] 包裹的时候,^ 符号会赋予 [] 反向的含义
# 正则表达式中定义匹配范围
正则表达式中定义匹配范围是指字符串中某一个字符的匹配成功条件在一个区间内,如个位数人民币的数值是 1 元,2 元,5 元,这个值区间就是 1,2,5。而正则表达式定义范围的是 [] ,|,()。
为了更好的比较区分效果,将在开头使用 ^ 结尾使用 $
var a = /^[123]$/; // 匹配 123 时为 false, 匹配 1 或 2 或 3 时为 true。所以 [] 是匹配中间数值某一个即算通过 | |
var b = /^(123)$/; // 匹配 123 时为 true, 匹配 1 或 2 或 3 时为 false,所以 () 匹配定义的完整字符串才算通过。这样写等价于 /^123$/ | |
var c = /^(123|321)$/;// 匹配 123 或者 321 时为 true; |
以上是范围的基本使用逻辑,还有细微细节。当然不同语言实现正则细节会有所变化。
[]:在 [] 当中大量的特殊字符串将成为一名普通的字符串,换句话说在 [] 当中需要前面加 \ 转义为普通字符串的有,[],^,-。其他特殊字符串如 (,),| 等放入 [] 后将是一个普通字符串。像 /[1]/
// \,[] 不转义,它们原来的意义一个是用于转义字符串,一个是前面说的逻辑。 | |
// ^ 在 [] 里面是【非】的意思,必须接在 [ 后面 | |
var a = /^[^123]$/;// 匹配 1 或 2 或 3 时为 false, 匹配非 1 或 2 或 3 的单个字符为 true | |
//- 在 [] 里面是【区间】的意思,有三种类型可使用。数字:[3-8] 代表 3,4,5,6,7,8,小写字母:[b-e] 代表 b,c,d,e, 大写字母:[C-F] 代表 C,D,E,F | |
var a = /^[a-z]$/; // 匹配 z 为 true。既满足最前位数,也满足最后一位数 |
(): 相比 [] 的单个匹配,() 就是组主要应用在限制多选结构的范围 / 分组 / 捕获文本 / 环视 / 特殊模式处理。() 内是填写的是 正则子模式 这个子模式模式可以理解为不用填写 / 开头和 / 结尾的正则。匹配 | 可以写多个正则子模式。
/(abc|bcd|cde)/.test("abc");//true abc、bcd、cde 三者之一均可为 true,顺序也必须一致 | |
"aaaaaabbbccceeee".match(/(aaa)(bbb)(ccc)(eee)/); // 会匹配出一对如下数组 ['aaabbbccceee', 'aaa', 'bbb', 'ccc', 'eee'] | |
"hello".match(/[a-z]{1}/g); // 输出 ['h', 'e', 'l', 'l', 'o'] |
// (?:ddd) 匹配 ddd 但不获取匹配结果,是一个非获取匹配。 | |
"aaaaaabbbcccdddeeee".match(/(aaa)(bbb)(ccc)(?:ddd)eee/); // 匹配出的数组为 ['aaabbbcccdddeee', 'aaa', 'bbb', 'ccc' | |
"aaaaaabbbcccdddeeee".replace(/(aaa)(bbb)(ccc)(?:ddd)eee/g,"#") // 输出 'aaa#e',将匹配数组的第一位替换为 # 。 | |
// (?=h) 匹配 h 前面的位置。 | |
"hello".match(/(?=h)/g); // 输出 ['']。因为匹配的是 h 前面的位置。hello 是由 ""+"h"+"" + "e" + ""+"l"+"" + "l" + ""+"o"+"" 组成的。 | |
"hello".replace(/(?=h)/g,"#"); // 输出 '#hello' | |
// (?<=h) 匹配 h 后面的位置 | |
"hello".match(/(?<=h)/g); // 输出 ['']。 | |
"hello".replace(/(?<=h)/g,"#"); // 输出 'h#ello' | |
// (?!h) 匹配除 h 匹配中的字符串前面位置 | |
"hello".match(/(?!h)/g); // 输出 ['', '', '', '', '']; 就是上面除了 "h" 前的 ""其它地方拼接的"" | |
"hello".replace(/(?!h)/g,"#"); // 输出 'h#e#l#l#o#' | |
// (?<!h) 匹配除 h 匹配中的字符串后面位置 | |
"hello".match(/(?<!h)/g); // 输出 ['', '', '', '', '']; 就是上面除了 "h" 后面的 ""其它地方拼接的"" | |
"hello".replace(/(?<!h)/g,"#"); // 输出 '#he#l#l#o#' | |
// 若想去掉开头的 # 可以使用 (?!^) 匹配除开头匹配中的字符串前面位置 | |
"hello".replace(/(?!^)(?<!h)/g,"#"); // 输出 'he#l#l#o#' |
# 正则表达式速查表
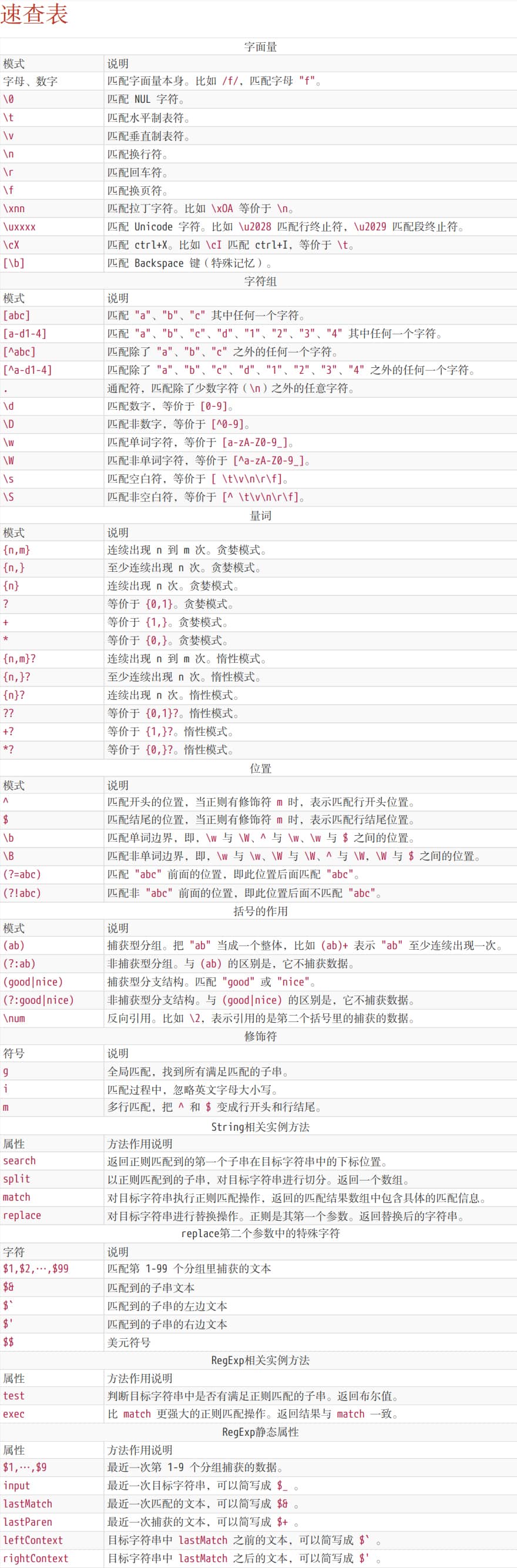
# 2021 年 10 月 25 号 暂时完结
把能想到的都测试并记录好了,不知道以后使用是否还有疑问,待补充。
(123)(321) ↩︎